

A curious and innovative project by a small team at EXO Labs has demonstrated a remarkable feat: executing a contemporary AI model on a computer dating back to 1997 — specifically, a Pentium II running Windows 98 equipped with only 128 MB of RAM.
This experiment, part of the group's open-source series, involved loading a pared-down variant of Meta’s LLaMA 2, a widely used large language model (LLM) in lightweight AI applications. Without relying on GPUs or advanced memory, the system exhibited understandably modest performance but captivated many AI enthusiasts with its possibilities.
“It demonstrates how thoughtfully redesigned transformer models can operate efficiently on minimal hardware,” explained Andrej Karpathy, an AI researcher and co-developer of the project’s code, which is publicly accessible on GitHub. “You don’t require massive data centers to run intelligent algorithms.”

Launching AI on Vintage Equipment
The Pentium II system was purchased from eBay at a price of £118.88. This vintage machine lacked USB connectivity and only had a 1.6 GB hard drive—meager by today's standards. Transferring data proved challenging: USB drives failed to function, and rewriteable CDs went unrecognized.
Ultimately, the team resorted to the long-established method of FTP over Ethernet, connecting a modern MacBook via a USB-C to Ethernet adapter and utilizing static IP settings to transfer the necessary files.
Transferring over the tokenizer, weights, and inference code was just the start; compiling the components proved complex. Current C++ compilers like mingw generated code incompatible with the Pentium II due to unsupported processor instructions such as CMOV.

The solution was to utilize an older compiler: Borland C++ 5.02, a 26-year-old environment compatible with Windows 98. This legacy IDE demanded careful coding practices, such as declaring all variables at the start of functions and replacing common timing functions like clock_gettime with Windows-native alternatives like GetTickCount().
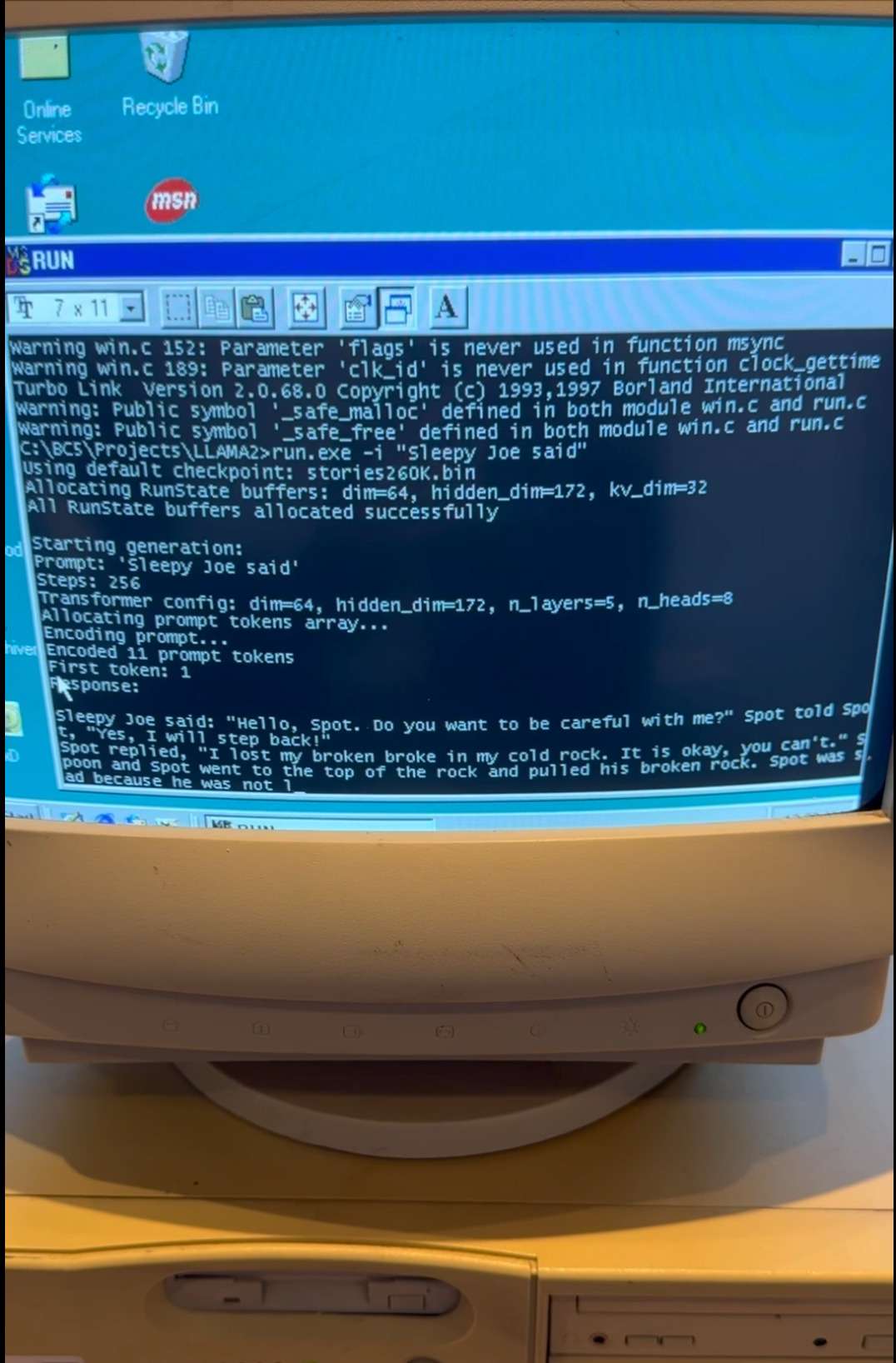
Once compiled, a reduced version of LLaMA 2 with 260,000 parameters successfully generated text at roughly 39 tokens per second. Larger iterations, such as the 15 million parameter model, operated at approximately 1.03 tokens per second, while a 1 billion parameter test (LLaMA 3.2) ran at a sluggish but functional pace of 0.0093 tokens per second.
Introducing BitNet: Efficient Compression for AI Models
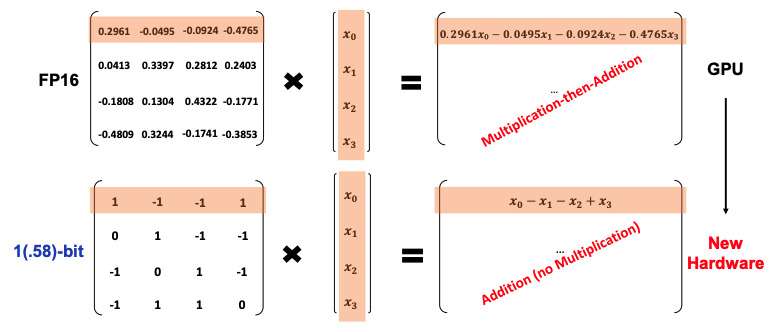
Central to this experiment is an innovative architecture called BitNet, developed by EXO Labs as a solution to the heavy computational requirements of current LLMs. BitNet employs ternary weights limited to -1, 0, or 1, considerably lowering memory and energy consumption.
This method, detailed in research presented at ICML 2024, allows a 7-billion parameter model to be compressed to just 1.38 GB. With some programming finesse, it is feasible to run such models even on retro computers. Microsoft’s benchmarks using BitCPP demonstrate model generation speeds of 52 tokens per second on a high-end M2 Ultra CPU, and 18 tokens per second on a standard Intel i7.
Even a 100-billion parameter BitNet model could potentially run on a single CPU at a rate of 5–7 tokens per second, comparable to average human reading speed. This advancement presents significant opportunities for low-power AI, edge devices, and improved AI accessibility in underserved regions.
“This kind of design challenges conventional wisdom in AI,” stated Chris Wellons, a systems engineer known for expertise in retro computing. “Success lies in smarter architectures, not just faster chips.”
Challenging the AI Hardware Paradigm
This achievement coincides with growing concerns regarding AI’s energy consumption and environmental impact. Training top-tier models like GPT-4 or Gemini 1.5 consumes energy comparable to powering entire small towns, according to the International Energy Agency.
By contrast, the Pentium II in this project peaks at only 27 watts. Coupled with BitNet’s demonstrated 50% energy efficiency gains over conventional models (source), running AI on minimal hardware offers promising environmental and practical benefits, especially in education, embedded systems, and healthcare sectors.
EXO Labs has already customized BitNet for protein sequence modeling, a promising AI-driven approach in drug discovery. They plan to develop a larger open-source BitNet model in 2025, targeting CPU-exclusive platforms for broad adoption.
Meanwhile, the team encourages the community to experiment, inviting hackers to test AI on vintage consoles, outdated smartphones, or Raspberry Pi devices, thereby democratizing AI through accessible hardware experimentation.












0 comments
Sign in to Comment